文章介绍
1 | 作者:Jonathan Salwan(@JonathanSalwan)和Romain Thomas(@rh0main) |
由于triton中文资料不多,学习使用triton具有阻碍。在阅读外文文章时发现此文,由于是法语撰写且为PDF格式,机翻阅读较为困难。于是借助gpt进行翻译并在尽可能保持原文含义的情况下手动修改部分名词对应的中文为惯称。
原文链接:https://www.romainthomas.fr/publication/triton/
———-以下为翻译内容———-
在这项工作中,我们提出了一种基于恶意代码模式检测的二进制反混淆技术。我们利用了混淆器倾向于使用相似技术来混淆代码的属性,并将这些编码模式用作指示混淆的指标。二进制混淆用于保护程序中存在的知识产权。存在多种类型的混淆,但大体上是修改二进制结构,同时保持相同的原始语义。其目的是确保原始信息被“淹没”在大量无用信息中,从而使逆向工程变得更加耗时。在本文中,我们展示了如何使用Triton框架分析混淆代码以节省时间。
1.Triton框架简介
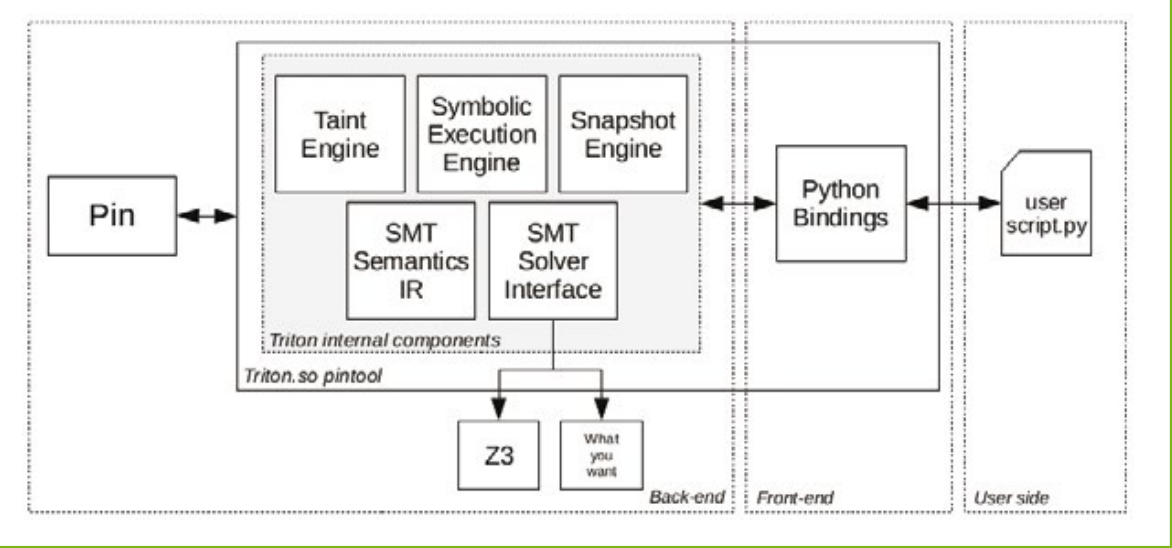
Triton[0]是一个动态符号执行(DSE,也称为混合符号执行)框架,于2015年与Florent Saudel一起在SSTIC上介绍。它被开发用于动态分析代码,无论是用于漏洞研究还是用于在混淆代码上提供逆向工程的帮助。 Triton框架由三个主要的“类别”组成,包括:
- 动态二进制插桩(
DBI)通过Pin实现。它的作用是获取与当前指令相关的具体上下文,然后将其传递给引擎。 - 引擎执行分析(通过
taint分析、符号执行、快照管理和将语义转换为SMT2-Lib[2])。 - 还包括一部分绑定,允许通过高级语言(如Python)控制引擎。
引擎是Triton的核心,并被建模为可以相互通信并可以从Python绑定中受到用户控制。图1说明了Triton的整体设计。其中的一些引擎将在接下来的章节中描述,以更好地理解第2章。
1.1 污点引擎
污点分析可在执行过程中保持对特定数据变化的视图。通常,用户输入会被标记为受到污点影响,而污点引擎的作用是跟踪这些输入的变化(与输入交互的指令,这些输入存储在哪里以及如何传播等)。除了跟踪数据变化外,该分析在Triton中有四个优点:
- 优点1:其第一个作用是帮助符号执行决定是否应该对内存地址的值进行符号处理或具体处理。通常,如果指令的源操作数未被标记,具体值就足够了。否则,当前值取决于用户指定的输入。因此,Triton使用源操作数的符号值。
- 优点2:其第二个作用是特例。污点分析和符号执行都使用相同的输入。对于第一种情况,它们代表着污点的传播源。对于第二种情况,这些被标记污染的内存单元是符号变量,符号执行将基于内存的污染标记构建符号变量。一个被标记污染但符号引擎未知的内存单元表示一个新的输入,因此必须创建一个代表该输入的符号变量。
- 优点3:污点还可以用作符号执行的过滤器。在跟踪期间,许多指令不会影响用户指定的输入(它们的操作数没有被标记)。因此,这些指令永远不会出现在路径条件的约束中。因此,没有必要对它们进行符号执行。通过污点分析实现的符号执行优化用于
MergePoint[3]和FuzzWin[4]。 - 优点4:最后,污点标记可以简单地用于可视化数据在执行中的传播。
将数据(如寄存器或内存单元)使用Python 提供的函数绑定进行着色(标记污染)是很容易的。API提供了taintReg()或taintMem()等函数。然后,引擎的作用是根据指令的语义通过寄存器和内存传播污点。清单1是一个Triton代码示例,该示例在调用main函数时将控制台参数的所有字节标记为着色的。
1 | #Listing 1 : 标记argv污点 |
1.2 符号引擎
在符号执行领域,存在两个主要方向,即静态符号执行(SSE)和动态符号执行(DSE)。SSE和DSE的选择取决于您正在执行的分析类型和可用信息。SSE主要用于验证给定代码的属性,而DSE用于构建与执行控制流和变量演变相对应的约束条件。符号执行的作用是生成与程序、路径或数据演变相对应的逻辑公式。类似于符号计算,它基于符号变量(或符号)。在这里,变量这个词具有数学含义。它代表公式中的未知数。换句话说,它是一个“自由”变量,因此可以被任何值替换。符号引擎的作用是创建并保留所有符号表达式,然后为程序的每个点建立表达式与寄存器/内存之间的联系。每个符号表达式都有一个独特的ID(符号引用),它是唯一的。
符号输入由<ID:Expr>对表示,这对组合保留在全局表达式集中。表达式可能包含对其他表达式的引用,这使我们可以将表达式保持在SSA(Static Single Assignment)[5]形式下。清单2说明了两个寄存器相加的表达式的SMT2-Lib表示形式。引用#40和#39表示分配给寄存器RAX和RDX的最后两个表达式。引用#41表示在执行此指令后,寄存器RAX的新表达式。
1 | Listing 2 : ADD指令 SMT2-Lib 表达式 |
1.3 用SMT2-Lib表示语义
SMT-Lib的版本2(我们称之为SMT2-Lib)是一个国际倡议的延续,旨在促进对可满足性模理论(SMT)问题的研究和开发。许多SMT求解器都支持这个新版本。因此,我们将我们的语义和约束转换为这种语言,而不是使用Z3的C++接口,这样以后就可以使用任何支持这个标准的SMT求解器。
1.4 符号表达式的抽象语法树
Triton将每个汇编指令转换为一个或多个SMT2-Lib表达式的列表。这种语言及其用途在前面的第1.3段中介绍过。一个SMT2-Lib公式是一个S表达式(symbolic expression,符号表达式),其语法与Lisp或Scheme语言非常相似。所有操作都是前缀形式的,并且一个良好形式的表达式都包含在括号中。
每个公式都有一个唯一的标识符(ID)来代表它。如果一个公式A依赖于公式B的值,它将使用B的ID而不是另一个公式。这个唯一标识符的原则来自于SSA。在本文后续部分中,我们将称这些公式以及这种中间表示为“SSA表达式”。
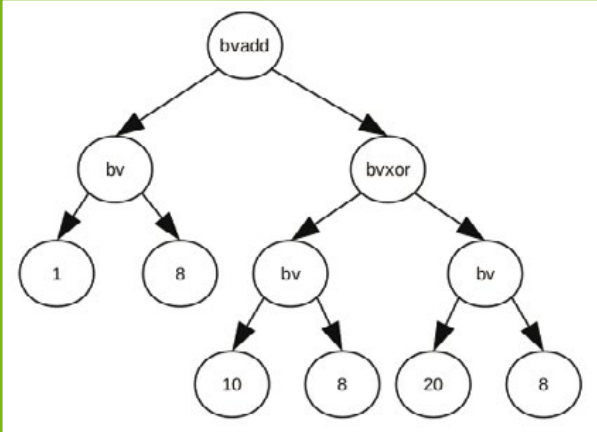
为了更轻松地操作这些表达式,所有表达式都可以通过抽象语法树(AST)进行操作。我们以清单3中的汇编代码片段为例。
1 | Listing 3 : 汇编代码 |
在第5行,寄存器AL的AST由图2所示。该AST表示了从程序点1 → 5开始的AL寄存器的语义。
从Python API中,可以创建和修改AST节点。清单4演示了这个功能。
1 | Listing 4 :操作AST代码 |
还需要注意的是,在Triton的框架中,AST的SMT2-Lib语法已经稍微修改了。增加了REFERENCE类型的节点。这使我们能够更轻松地处理子图,并独立于父图且符合SSA。REFERENCE类型的节点是终止节点,但是引用了子图。图3说明了这个过程。
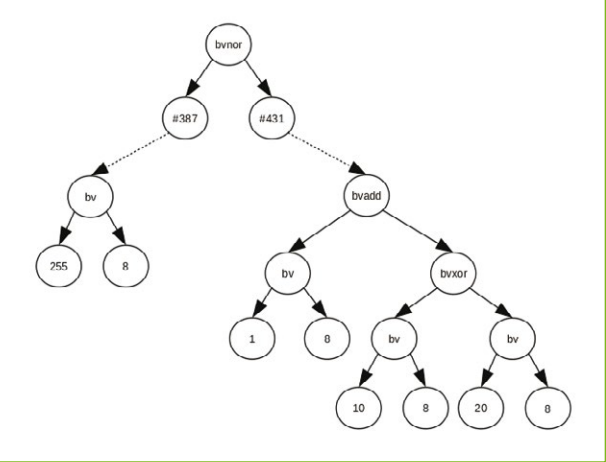
由于REFERENCE类型的节点是终止节点,API提供了可以重新构建包含引用的表达式完整图的功能。为此,Triton遍历初始表达式,并递归地替换所有REFERENCE类型的节点为其各自的图。下面的清单5演示了从API重建图的过程。
1 | Listing 5 : 重建含有REFERENCE节点的图 |
(翻译注:Triton使用AST作为中间表示来表示指令的语义,这使得其可以进行符号执行,进行数据流分析和其他静态分析,同时也可以将其与SMT solver集成,以解决关于二进制程序的复杂问题。)
2.O-LLVM
在本章中,我们将展示如何使用Triton来定位和分离所需的信息,而不必担心混淆。我们将使用Obfuscator-LLVM的免费解决方案进行演示。O-LLVM基于LLVM IR,并提供了三种类型的Pass
- 替换(Substitution),它将逻辑操作的标准形式替换为位操作[7]。
- 虚假控制流(Bogus Control Flow),它在原始的基本块之前添加基本块,并设置不透明谓词来指向原始基本块[8]。
- 控制流平坦化(Control Flow Flattening),它将控制流图(
CFG)平坦化[9,10]。
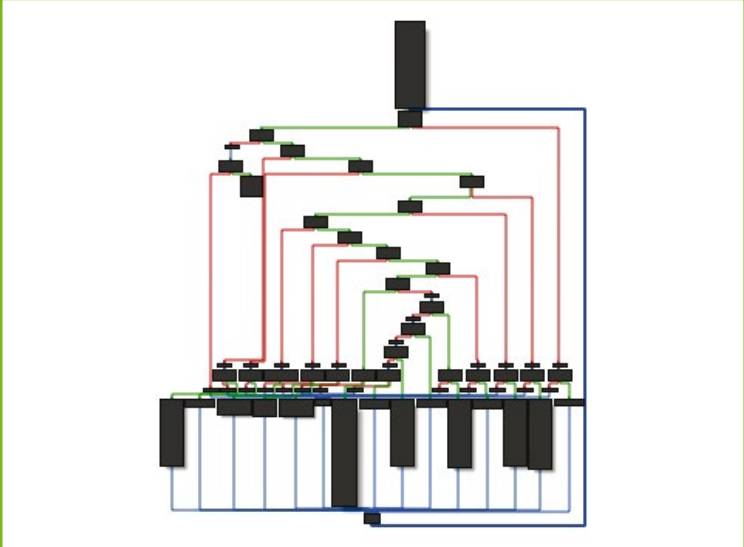
为了简单地说明 Triton 中的功能如何帮助分析师分析混淆的二进制文件,我们编译了一个包含 O-LLVM 所有选项 (-mllvm -sub -mllvm -fla -mllvm -bcf) 的简单二进制文件。编译后的二进制文件需要输入一个有效密码,其 CFG 如图4所示。
请注意,O-LLVM的保护分析已经在Francis Gabriel和Camille Mougey的文章中进行过描述[19]。该分析是基于Miasm框架[20]的静态分析实现的。我们提供了另一种基于动态分析的方法(两种方法互补)。
2.1 确定数据入口点
在逆向工程中,主要的重点是查找信息并理解这些信息的处理方式。而代码混淆则是为了尽可能地使这两个原则变得更加困难。
在开始分析之前,我们需要找到用户数据。这样可以为真正有趣的内容提供一个分析起点。我们知道,从用户处接收的数据最初以明文形式存储在内存中。因此,我们开发了一个 Triton 工具 [11],它可以列出所有的内存访问,从而确定第一个将获取用户数据的指令——这为我们提供了一个分析起点。
列表6呈现了工具的输出结果。输入 A(0x41)被作为目标程序的参数,可以看出,处于0x4008c1的指令是第一条处理该输入的指令。我们现在可以从这个地址开始我们的分析。根据经验,在执行网络通信或解析时,这种搜索方法非常有用。
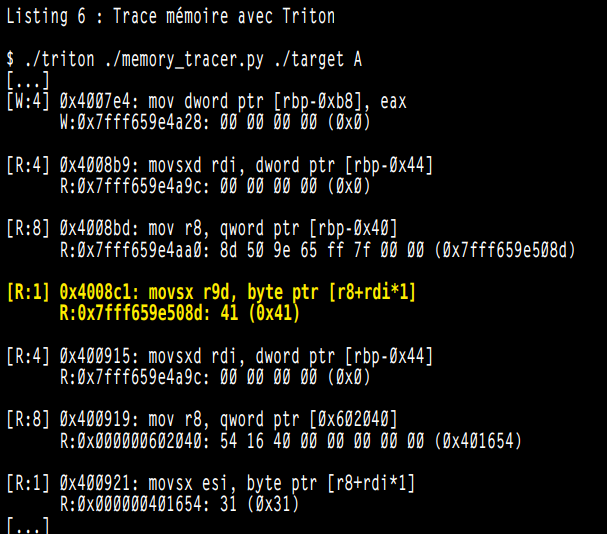
2.2 隔离的追踪
找到处理用户输入的第一条指令是一件事,但是隔离所有与用户输入相关的指令则是另一回事。为了能够在执行过程中跟踪用户数据,Triton提供了一种污点引擎。
通过污点分析,可以在某个时刻标记数据,然后根据每条指令的语义,在执行过程中将标记传播到寄存器和内存中。在处理混淆的二进制文件时,这种方法可以节省宝贵的分析时间。
为了能够离线处理跟踪,我们开发了一个Triton工具[12],用于将跟踪的整个执行上下文保存在数据库中,数据库的结构如清单7所示。
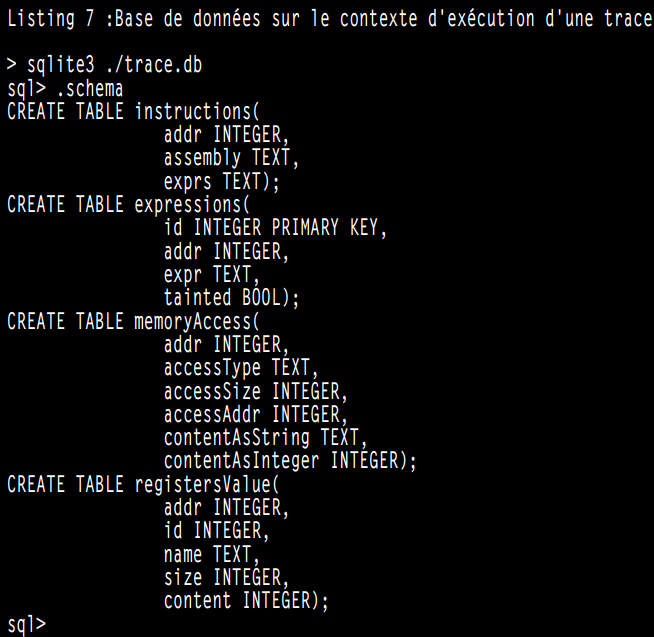
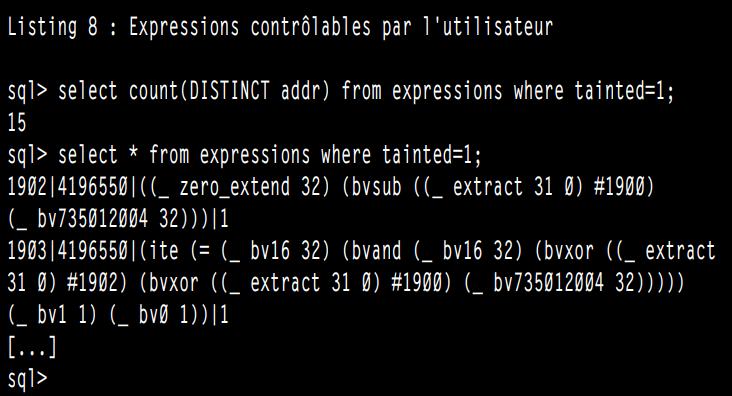
在标记用户输入点(第2.1章)后,将创建一个包含有关跟踪的所有信息的数据库,包括可以被用户控制的表达式(清单8)
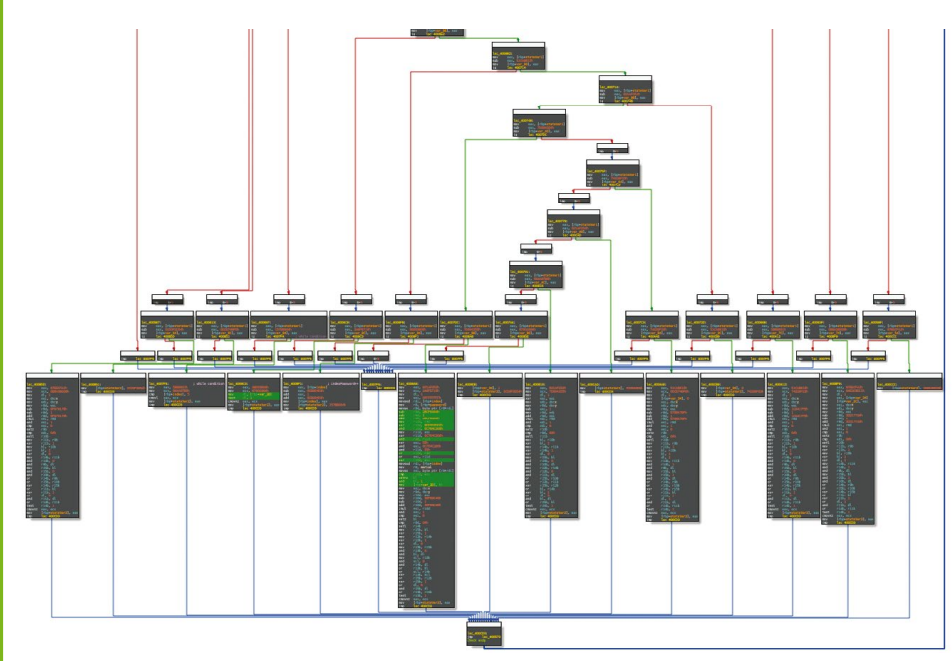
拥有包含执行上下文信息的数据库可以辅助逆向工程。我们已经开发了一个IDA插件,可以将Triton的动态信息与IDA的静态信息相结合,如显示着色、每个指令中寄存器的值、代码覆盖等等。如图5所示,通过着色分析可以快速定位我们感兴趣的指令。我们还注意到,尽管进行了混淆,数据流并没有传播到所有基本块中,这使得我们可以更容易地针对符号分析进行目标定位。
2.3 符号化约束
在定位与用户输入有交互的代码块(清单9)之后,可以对该代码块进行符号执行,从用户输入点作为符号变量开始,直到达到所需的约束条件。
1 | Listing 9 : 由污点分析分离出的代码片 |
符号执行可以帮助我们解决一个或多个约束(例如,密码中的每个字符),而不必担心理解程序的语义——这在混淆的环境中,是节省分析人员时间的一种方式。Triton正是为了能够在两个点之间应用符号分析而设计的。为此,需要首先在第一个点声明一个符号变量(清单10),然后在第二个点创建一个约束(清单11),最后请求一个满足约束条件的求解器模型(清单12)
1 | Listing 10 : 在R9寄存器上创建符号变量 |
获得的model对应于期望密码的第一个字符。通过重复这个过程或者使用回放引擎[13]自动化这个过程,密码可以在很短的时间内被发现(不到一秒)。这个操作也可以应用于简单的哈希函数[14]。
2.4 表达式替换混淆分析
往往在混淆的代码中,通过求解符号约束以获取特定分支、恢复密钥或甚至生成冲突(不懂)并非是全部目标。在某些情况下,恢复原始算法并简化混淆表达式是很有意义的。
有几种方法可以用来隐藏逻辑操作。最常见的是按位操作(bitwise operation [15],请参见清单13),但还有更复杂的操作,如混合布尔算术(Mixed Boolean-Arithmetic,MBA)[16]。
在O-LLVM中,逻辑操作被转换为按位操作。为了简化表达式,首先需要分离表示按位操作的原子模式(pattern)。一旦分离出模式,目标是创建一个输入为模式树的转换,并返回一个简化的新树。对于每个转换,需要证明输出树的结果对于Z中的所有x都等于输入树的结果。
1 | Listing 13 : xor可能的代换位操作 [17] |
重新审视清单9中的代码,并使用Triton提取出符号表达式,我们得到以下混淆表达式:
1 | Listing 14 : 来自 listing 9 的表达式 |
在这个表达式中,可以分离出多个模式。最容易分离的模式是 ((a − b) − 1) + b) ,可以通过操作 (a − 1) 进行代换(证明1)。
1 | 证明 1 : ((a − b) − 1) + b) = (a − 1) |
一旦替换完成,得到的表达式如图6所示。为了更好的可读性,该表达式被分为两部分。同时,我们也知道形如 a ⊕ UINT64_MAX 的表达式可以被转换为 ¬a(证明2)。
1 | 证明 2 : (a ⊕ UINT64_MAX) = ¬a |
进行此转换后,我们可以发现在每个部分中,模式 (¬a∧b)∨(a∧¬b) 出现了两次。因此,完整的表达式为:(¬a∧b)∨(a∧¬b)⊕(¬c∧b)∨(c∧¬b)。每个部分的模式都是 ⊕ 的按位操作(参见清单13的第一个操作)。因此,每个部分都可以通过 a ⊕ b 进行代换(证明3)。
1 | 证明 3 : (¬a ∧ b) ∨ (a ∧ ¬b) = (a ⊕ b) |
应用此转换后,我们得到以下表达式:(a⊕b) ⊕ (c⊕b),它可以转换为 a ⊕ c(证明4)。
1 | 证明 4 : (a ⊕ b) ⊕ (c ⊕ b) = (a ⊕ c) |
这种类型的转换在SMT求解器中是很常见的,因此可以很容易地进行简化,而无需进行模式匹配(简化1)。
1 | 简化 1 : (a ⊕ b) ⊕ (c ⊕ b) → (a ⊕ c) |
因此,可以得出结论,清单9中混淆过的表达式可以通过表达式 ((SymVar0 − 1) ⊕ 85) 进行简化表示。
在O-LLVM框架中,按位操作的标准形式已知 [18],因此可以很容易地通过从AST中进行模式匹配来将其分离和简化。最复杂的情况是按位操作的标准形式未知。这正是Adrien Guinet进行的位运算符号计算的研究领域。通过在特定空间中简化这些操作,可以相对容易地识别出纯布尔运算。至于算术运算,通过某些启发式算法,可以找到比原始版本更容易理解的版本。
2.5 控制流平坦化混淆分析
图平坦化(graph flattening)是一种常见的静态分析保护措施。它的目的是将基本块“展开”,以便其关系不再可见。为了更好地理解其工作原理,我们采用清单15的代码作为例子。其CFG由图7所示。
1 | Listing 15 : 示例代码 |
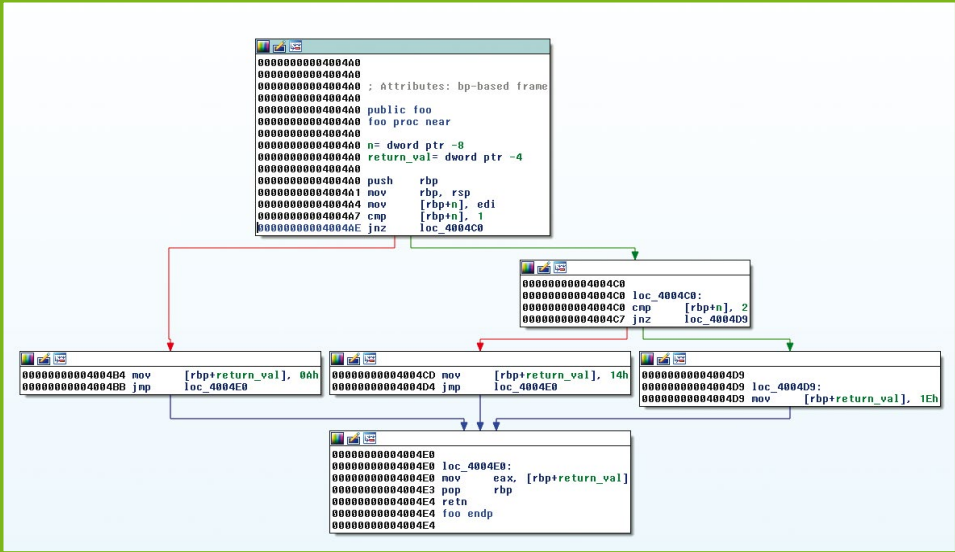
控制流平坦化会修改CFG,以便不再显示不同基本块之间的关系。为此,该图将被转换为类似于状态机的形式。转换后的图形代码可能类似于清单16,并且其图形由图8所示。
1 | Listing 16 : 清单15经过控制流平坦化后的示例代码 |
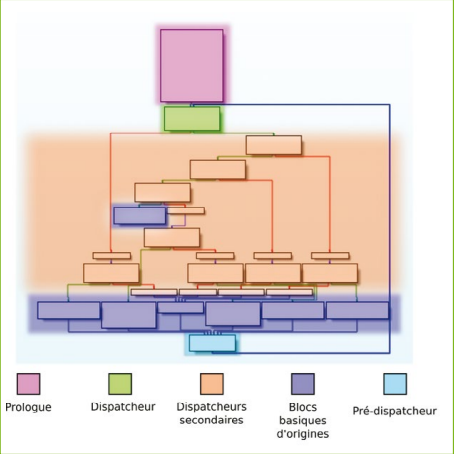
通常,CFG类似于一个大型switch语句,其可能的值是状态,其内容表示原始的基本块。 对于O-LLVM的图形平坦化,状态之间的转换并不像清单16的示例那么简单,但原理仍然相同。通过其图形(图8),我们可以看到其具有与图9相同的结构,可以利用Triton的符号执行和污点引擎以以下方式帮助我们找到基本块之间的关系:
- 在程序的开头,我们将其输入为标记污点。这可能是参数,文件,系统调用等。
- 接下来,我们继续执行程序,直到到达原始图形的基本块。请注意,我们假设已经确定了程序原始的基本块(或至少是其中的一部分),并且只需要查找它们之间的关系。
- 在已识别的基本块中,如果一条指令调用了一个标记为污染的内容(内存地址或寄存器),则将其转换为符号变量。这样可以避免在整个程序上进行符号执行,而只需在感兴趣的部分上执行。通过这种方式,符号表达式的大小减小了,并且更容易进行分析。
- 在基本块结束时,我们根据符号变量获取所有可能的状态。由于每个状态对应一个基本块,因此我们获得了所需的关系。由于条件是符号变量的值,因此为了找到状态和基本块之间的对应关系,可以使用Triton的快照引擎。这使我们能够在程序开头注入所需的状态,并查看我们到达了哪个基本块。
2.6 虚假控制流分析
Bogus Control Flow也是一种防止静态代码分析的保护措施。它通过添加永远不会在程序执行期间到达的基本块并与原始图的基本块混合在一起,使得很难区分哪些是可执行的,哪些是不可执行的。具体而言,O-LLVM插入了一个不透明的谓词,用于进行条件跳转。由于这个谓词具有常量值(真或假)且独立于程序输入,因此跳转执行后的指令地址将始终保持不变。
这个谓词是使用两个变量 X 和 Y 构建的。因为在二进制中有控制流混淆,所以图中并没有跳转到某个地址,而是状态的改变。让我们来看看地址为0x400816的基本块(图10)的情况。

我们可以看到,这里使用了两个状态,但其中一个状态永远不会被放入状态变量中。条件是通过CMOVNZ指令实现的,如果R15B不等于1,则将状态2(0x7d094355)放入EAX中,否则将状态1(0x621af252)放入其中。因此,R15B包含不透明谓词的公式,而EAX包含状态。因此,我们可以对包含变量X和Y的EDI和R8D寄存器进行符号执行,然后查看是否存在一种解决方案,使EAX等于状态1或2。由于这是一个不透明的谓词,只有两个状态中的一个会有解决方案。
以下是Triton如何帮助我们分析这些块的方法。我们定义了两个变量X和Y的地址(清单17)。
1 | Listing 17 : 定义x,y的地址 |
然后,我们定义要分析的基本块的地址列表(清单18)。
1 | Listing 18 : 定义基本块列表 |
最后,我们指定了分发块的地址,因为我们确信在这个基本块中已经计算出了状态(清单19)。
1 | Listing 19 : 指定分发块地址 |
“enabled“是一个变量,用于指示我们是否在由Bogus Control Flow修改的基本块中。第一个类型为AFTER(在指令之后调用)的回调用于将用于包含变量X和Y的寄存器转换为符号变量(清单20)
1 | Listing 20 : 将寄存器转换为符号变量 |
if语句中的条件检查指令是否读取了其中一个变量的内存地址。此外,由于基本块使用变量X和Y,因此我们处于虚假控制流中所以将enabled置位True。
第二个类型为BEFORE(在指令之前调用)的回调将用于确定将永远不使用哪个状态(清单21)。
1 | Listing 21 : 确定两种可能性 |
“EtatSymId“包含符号表达式的标识符。”GetFullExpression“将返回完整的SMT表达式,而”GetState“将解析AST以提取两个可能的状态。需要注意的是,代码使用了存储在RAX中的符号表达式,而不是存储在变量”etat“中的表达式。这不会影响代码的一般性,因为在所有基本块中,在将状态存入内存之前,状态都位于寄存器EAX中。
然后,需要确定哪个状态将永远不会被使用。为此,我们尝试为两个可能的状态求解方程。如果方程无解,则表示该状态不可访问(清单22)。
1 | Listing 22 : 确定不可达的状态 |
通过查找状态和基本块之间的对应关系,我们可以找到无法访问的基本块。最后,我们对所有寄存器和内存地址进行具体化,以避免出现级联符号表达式(清单23)。
1 | Listing 23 : 具体化寄存器和内存 |
在二进制文件上执行这个脚本[21]的结果如清单24所示。
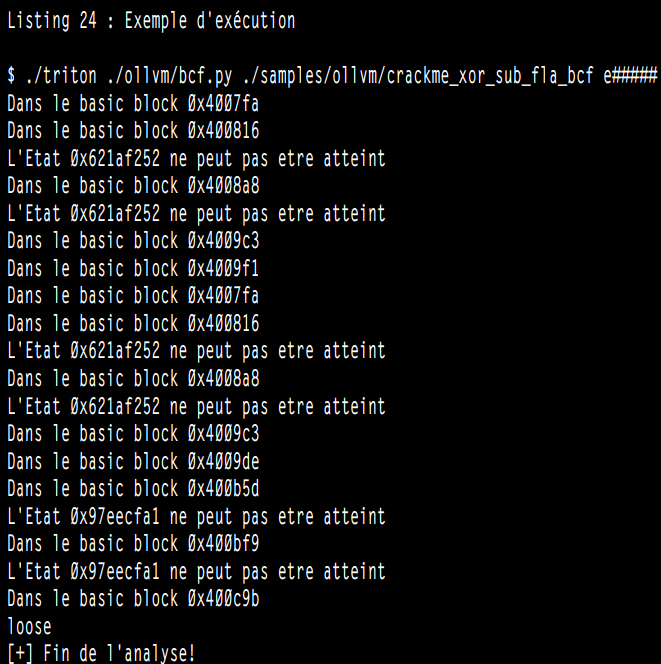
前面的结果并不是无法访问状态的详尽列表,而只是在执行过程中遇到的状态。使用其他输入(在我们的情况下是其他参数)进行执行可能会产生更多(或更少)的不可访问状态。由于这些保护措施是针对静态分析的,因此动态分析“正常”能够解决这些问题。然而,与静态分析不同,动态分析不能够全面分析,因为它的分析基于执行跟踪。但是,它可以访问上下文,因此可以更轻松地针对并分析程序的某些部分
总结
Triton是一个二进制分析框架,提供了额外的组件来帮助逆向工程。在这篇文章中,我们试图展示使用Triton分析混淆代码的用例,但是Triton也可以用于调试或漏洞研究。需要注意的是,所分析的保护措施(O-LLVM)是一种公共保护措施,这使得反混淆更容易。实际上,对于一种保护措施来说,真正的挑战在于在公开其工作原理的同时保持相当难以分析。同时需要认识到,保护措施并不是为了防止分析,而只是为了减缓分析的速度。例如,如果我们以游戏为例,并假设对于游戏发行商来说,最大的利润是在游戏发行的第一周内,那么保护措施至少需要保持一周,并且在保护措施上花费的成本必须与获得的利润成比例。
致谢:
感谢Aurélien Wailly邀请我撰写本文。
参考资料:
[0] http://triton.quarkslab.com
[1] https://www.sstic.org/2015/presentation/triton_dynamic_symbolic_execution_and_runtime_analysis/
[2] http://smt-lib.org
[3] Thanassis Avgerinos, Alexandre Rebert, Sang Kil Cha, and David Brumley. Enhancing symbolic execution with veritesting.
[4] https://github.com/piscou/FuzzWin/
[5] https://en.wikipedia.org/wiki/Static_single_assignment_form
[6] http://o-llvm.org
[7] https://github.com/obfuscator-llvm/obfuscator/wiki/Instructions%20Substitution
[8] https://github.com/obfuscator-llvm/obfuscator/wiki/Bogus%20Control%20Flow
[9] https://github.com/obfuscator-llvm/obfuscator/wiki/Control%20Flow%20Flattening
[10] T László and Á Kiss, Obfuscating C++ programs via control flow flattening, Annales Univ. Sci. Budapest., Sect. Comp. 30 (2009) 3-19.
[11] http://triton.quarkslab.com/documentation/tools/#3
[12] http://triton.quarkslab.com/documentation/tools/#4
[13] http://triton.quarkslab.com/documentation/examples/#10
[14] http://triton.quarkslab.com/blog/first-approach-with-the-framework/#5.2
[15] http://en.wikipedia.org/wiki/Bitwise_operation
[16] Yongxin Zhou, Alec Main, Yuan Xiang Gu, and Harold Johnson. Information hiding in software with mixed boolean-arithmetic transforms
[17] http://en.wikipedia.org/wiki/Exclusive_or
[18] https://goo.gl/noulwm
[19] http://blog.quarkslab.com/deobfuscation-recovering-an-ollvm-protected-program.html
[20] https://github.com/cea-sec/miasm
[21] http://triton.quarkslab.com/files/break_ollvm_bcf.py